Learning Transferable Visual Models From Natural Language Supervision(从自然语言监督中学习可转移的视觉模型)
概述
使用自然语言(而不是固定的类别固定的标签)训练视觉模型,“可转移”就是说,以往视觉模型只能够推理出固定的类别,例如ImageNet有1000个类别那你只能判断出那1000个类别(因为你在学习过程中就已经把类别和标签定死了),但是clip不一样,clip可以预测1000个类别以外的东西,并且clip不需要在ImageNet上再进行微调(在以往对于不同的数据集是需要重新训练模型的而clip不需要重新训练,这就是zero-shot)。作者为了证明clip的效果,在高达30多个数据集中做了实验,证明了clip的性能。
创建数据集
作者提出之前的工作效果不够好有很大一部分原因是因为之前工作用来训练模型的数据集不够大,为了训练clip模型作者创建了一个拥有4亿个文本对的数据集,叫做WIT。
选择训练方法
在最开始,图像用cnn提取特征,文本使用text transformer,目标是预测图片对应的文本,但是效率很低。
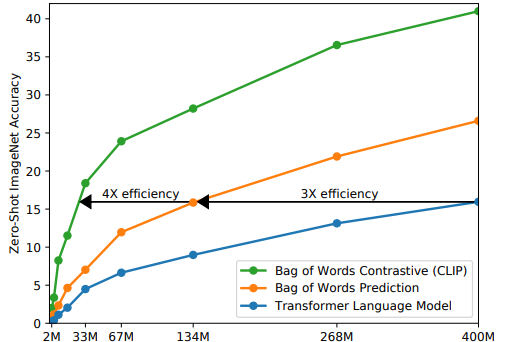
后来注意到对比学习的研究,对比学习的效果更好,作者探索了一个训练体系,改为预测哪个文本作为一个整体与哪个图像配对,效率大幅度提高。
如何训练和推理
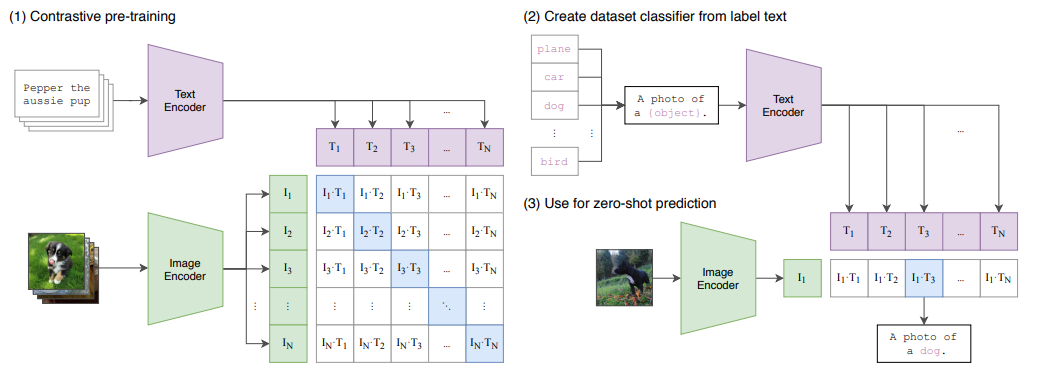
训练
给n张图片和n个文本,那么文本和图像的组合一共有 N x N 个,对角线的为正样本其他全部负样本(下图),正样本N * N个,负样本N * N - N 个,目标是最大化正样本的余弦相似度,最小化负样本的余弦相似度。
推理
先把单词变成句子,然后使用文本编码器获取特征。把照片给图片编码器,获取图片特征,用图片特征和文本特征算余弦相似度,取最大值(简单来说就是输入一张图片,然后一句话一句话问,你是不是飞机?你是不是狗?你是不是人?)。
Promet Enginerring & Promet Ensembling
promet是提示词
解决了什么问题?
一词多意
每个词语通常是有多个不同的意思的,例如“苹果”,可以是水果,也可以是一 个手机品牌。
怎么解决?
使用提示模板:
A photo of a {label}.
对于不同的数据集可以把提示模板扩充:
例如对于动物的数据集:
A photo of a {label},a type of pet.