High-Resolution Image Synthesis with Latent Diffusion Models(基于潜在扩散模型的高分辨率图像合成)
Introduction
作者指出传统的扩散模型作用在图像的像素空间,这将带来非常庞大的计算量。作者将扩散模型应用在了图像的浅空间中,并且引入了交叉引入交叉注意力层用于文本等一般条件输入。
Image Compression
作者选用的是autoencoder
Latent Diffusion Models
作者首先介绍了扩散模型,潜在扩散模型就是作用于低维的潜在空间。
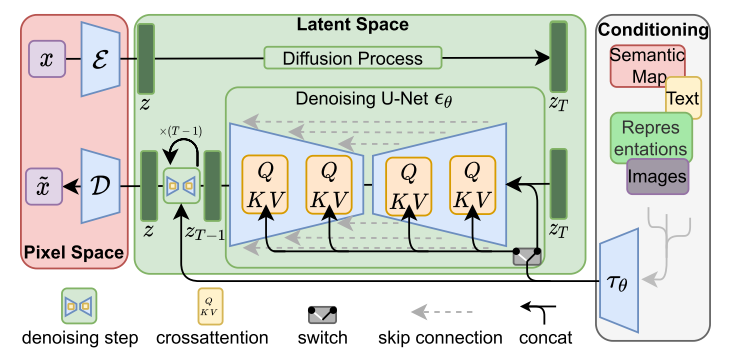
在下图中,Pixel Space是像素空间,Lantent Space是潜在空间,Conditioning是条件输入。像素空间X经过压缩操作得到Z,将Z进行扩散模型前向传播就有了ZT,如果有条件输入,在Conditioning中将条件输入投影为T,将ZT和Tconcat送进U-net学习噪声,得到ZT-1的潜在空间,然后继续反向,直到得到Z0,最终Z0解码生成新的X。
Conditioning Mechanisms
先把条件输入投影到中间表示T,在U-net的跳跃连接引入了交叉注意力机制,KV来自条件输入,Q来自潜空间。
相关知识
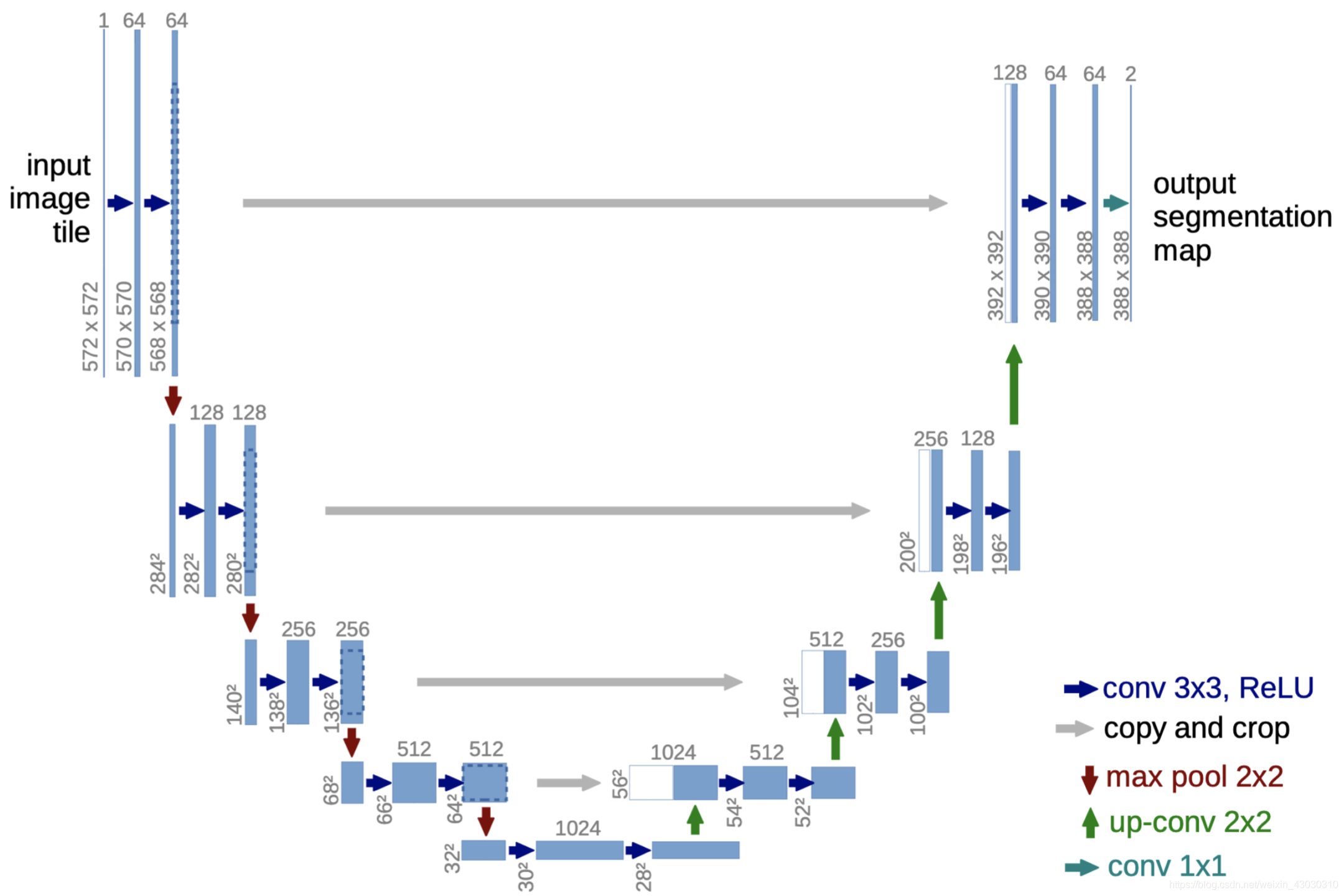
扩散模型的主要网络结构是U-net,所以我学习了一下U-net。
U-net
实际上左侧在做卷积和下采样的操作,空间维度在不断的变小,右侧在做卷积上采样操作,空间维度在不断的升高。
左右两边对齐的空间维度相同,这样可以进行concat的操作(右边会有一半是白色的)。
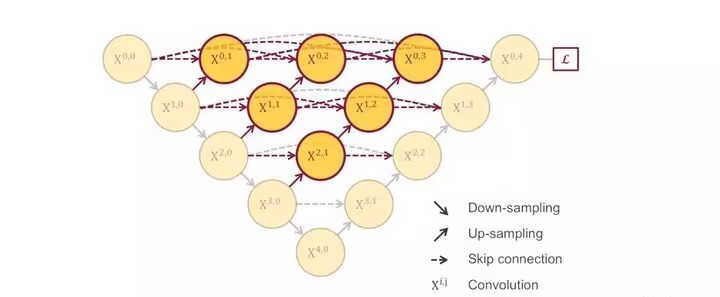
U-net++
在U-net中,我们对同样大小的特征进行了拼接实现了特征融合,但是有一个问题,在最开始时我们的特征只能表达出很浅显的东西,随着网络越来越深,特征能够表达的东西也越来越多,这样的话,对两个差距很大的特征进行融合是不是有些不合适?
U-net++解决了这样的问题。
例如:我们只需要对X10进行上采样,然后X00就可以和它拼接。
同时U-net++也添加了损失函数。