Diffusion-based Blind Text Image Super-Resolution
简介
标题:基于扩散模型的盲文本图像超分辨率
论文链接:CVPR 2024 Open Access Repository (thecvf.com)
代码链接:https://github.com/YuzheZhang-1999/DiffTSR
核心思想:
文章中提出了两种扩散模型,一个多模态混合模块:
- 图像扩散模型(IDM):用于恢复高分辨率文本图像,重点在于建模复杂文本样式。
- 文本扩散模型(TDM):用于识别文本结构,帮助纠正文本图像中的错误结构。
- 多模态混合模块(MoM):使IDM和TDM在每个扩散步骤中相互协作,互相提供改进的条件输入。
Baseline
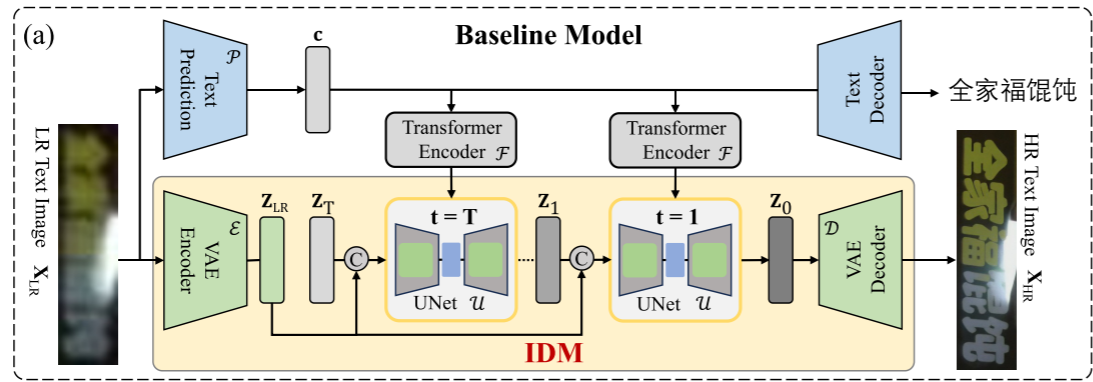
上半部分是文本识别模型,下半部分是图像扩散模型。
文本识别模型:从低分辨率图像通过TextPrediction(实际是transformer)预测出文本预测c,这个c需要在每一步的去噪步骤中都需要通过transformer传入Unet中。
图像扩散模型:在变分自编码器的浅空间中执行扩散的正向和反向过程,高分辨率图像图像经过VAE的编码器映射到潜在空间,不断加噪,接着通过噪声预测网络在反向扩散过程中逐步去噪。为了保证高分辨率图像的结果,作者将原始低分辨率图像的潜在空间特征与每个时间步特征拼接在一起进行重建。此外,文本先验c也被用作反向扩散的另一个条件(通过交叉注意力机制)。当然,在推理阶段,只输入低分辨率图像,随机采样高斯噪声。
Diffusion-based Blind Text Image SuperResolution
作者觉得Baseline还有改进空间,作者在Baseline上面进一步改进。
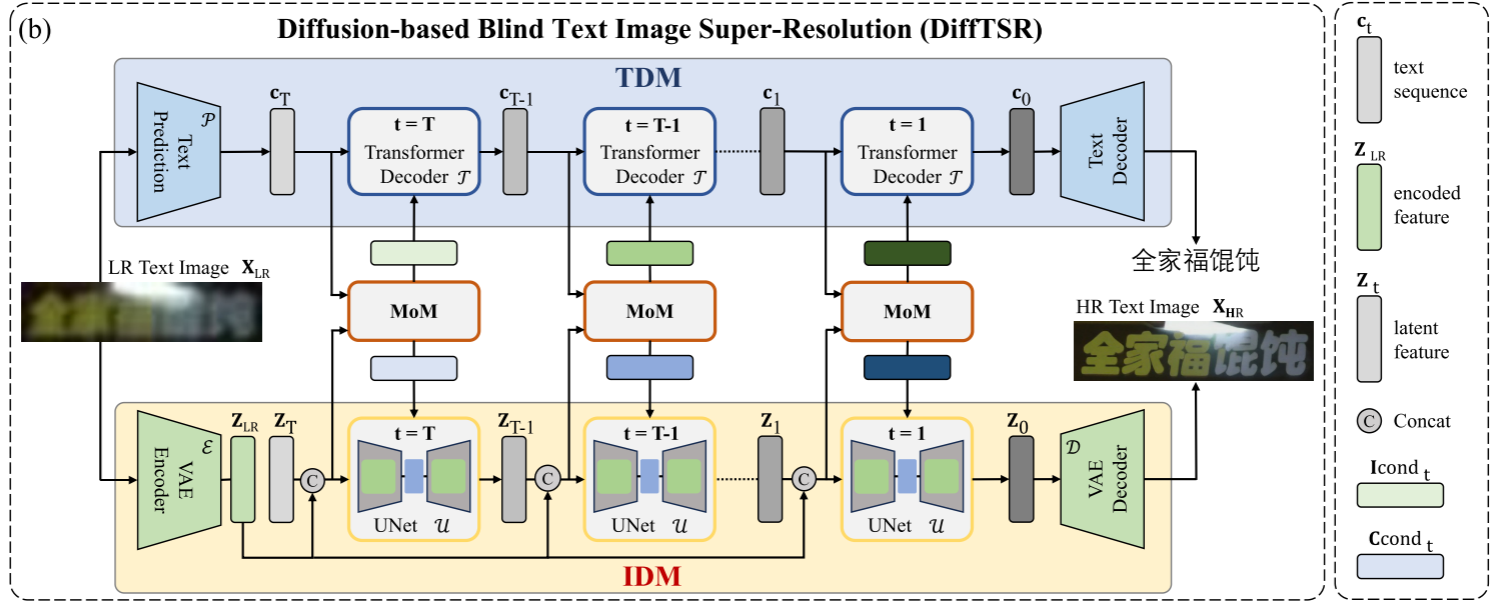
文本扩散模型(TDM):这部分没有太理解,文中给出了相关论文。我的理解是,用transformer预测出当前时间步的文本序列(因为每个时间步得到的信息不一样,预测的应该不一样),然后通过当前时间步的文本序列、当前时间步带有噪声的文本序列、当前时间步,预测前一个时间步的文本序列概率分布,然后采样前一个时间步带有噪声的文本序列。
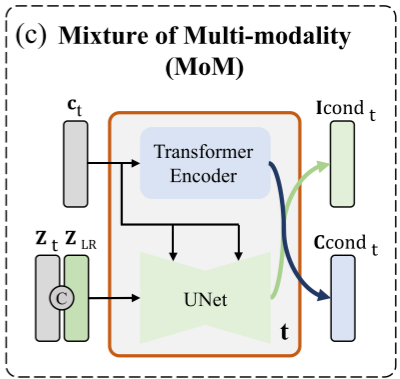
多模态混合模型(MoM):
- 为 IDM 提供文本条件:把TDM输出的文本序列状态送入TransformerEncoder,通过Transformer编码器将文本序列编码为文本条件,生成供 IDM 使用的文本条件。
- 为 TDM 提供图像条件:将IDM生成的图像潜在特征与低分辨率图像的特征进行拼接,通过U-Net提取图像的中间信息,同时结合当前的文本状态(通过交叉注意力机制融入),生成供 TDM 使用的图像条件。
图像扩散模型(IDM):通过交叉注意力接受来自MoM的条件,完成扩散。