MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation
标题:用于控制图像生成的融合扩散路径
| 链接:[MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation | OpenReview](https://openreview.net/forum?id=D4ajVWmgLB) |
代码链接:https://github.com/omerbt/MultiDiffusion
这篇文章介绍了一种可控的扩散模型,可控表现在指定分辨率、长宽比等。这项工作具有通用性,不像其他的工作只能做到其中的部分功能,比如说只能改变分辨率,只能改变长宽比,这项工作把这些功能结合到了一起。
MultiDiffusion
首先需要一个预训练好的普通的扩散模型做为参考模型,一般来说这个模型是生成固定的长宽比、固定的分辨率的,MultiDiffusion可以在与原始图像不同的图像空间上构建新的图像(不需要额外的训练和微调)。
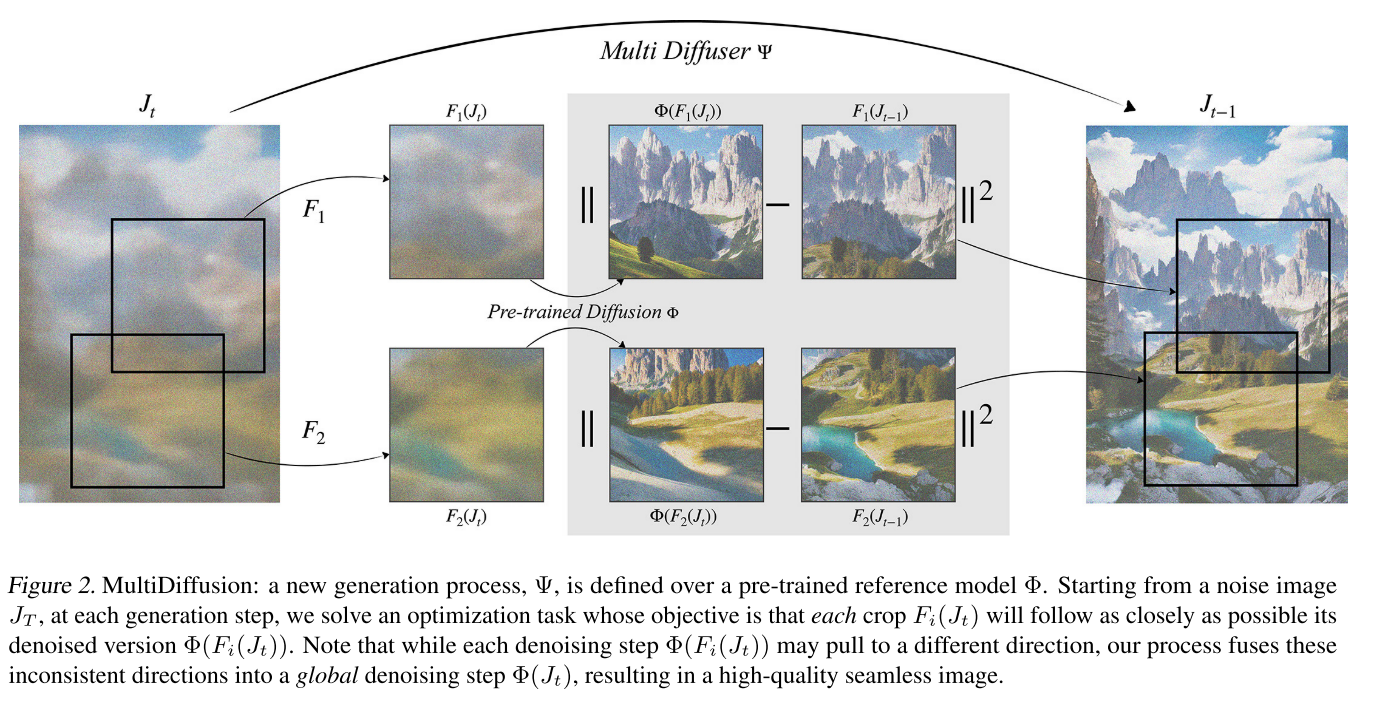
MultiDiffusion中定义了从目标图像空间到参考图像空间的映射,以及从目标条件空间到参考条件空间的映射。它是这样工作的,最小化损失函数FTD,通过这个损失函数反向传播来更新图像。
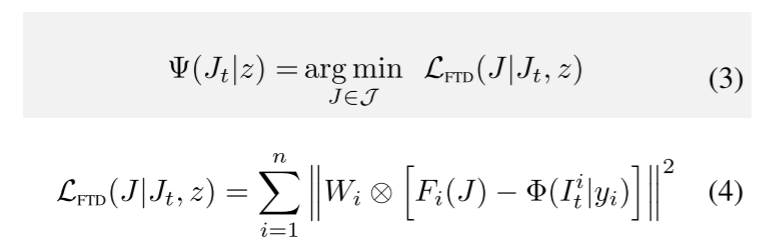
其中:
W:每个像素的权重矩阵。
F:目标图像通过映射函数将目标图像空间映射到参考模型的图像空间。
Φ:参考模型对于映射过来的局部区域的去噪输出。
上述方法做到的是对局部图像的更新,但是这些局部图像是重合的,这些重合部分通过公式5来处理(求均值)。
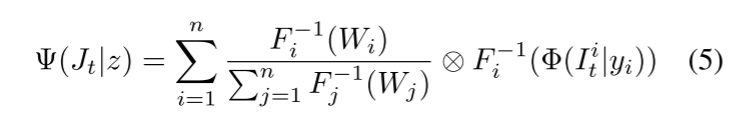
公式5是这样计算的:
Wi代表当前这个小区域的权重,Wi元素级乘参考模型输出后的逆映射(文中给出了解释,当FTD为0时,参考模型去噪输出的逆映射就是目标图像的局部去噪),然后元素级除权重矩阵元素级和。
最后文章给出了两个实例。第一个实例生成一个长宽比与原来不同的全景图,有n个裁剪区域,每个裁剪区域权重为1;第二个实例,用不同文本提示词指定不同区域生成不同内容,这个目标图像空间得和参考模型的图像空间一致,有n个不同的文本提示词,每个文本提示词对应一个图像掩码作为权重。重点在于n是什么。
总结
所谓映射在第一个实例中,实际就是目标空间位置映射到参考模型空间位置;在第二个实例中,没有映射,融合体现在了多个不同的文本提示词引导不同区域生成不同图像。