DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks
这篇文章由华南理工大学撰写,发表在2024CVPR上。
标题:文档图像恢复任务的通用模型
链接:CVPR 2024 Open Access Repository (thecvf.com)
代码链接:[ZZZHANG-jx/DocRes: CVPR 2024] DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks (github.com)
文章指出目前方法通常针对单一修复任务设计专用模型,本文试图通过统一多个修复任务(如去扭曲、去阴影等),解决目前方法的复杂性问题。本文提出了动态任务提示(DTSPrompt)。通过为每种修复任务设计特定的视觉提示(不同任务对应不同的特征提取),模型能够灵活调整以应对不同任务。DTSPrompt 提供了任务的额外信息,不仅指导模型执行任务,还能提升模型的整体效果。
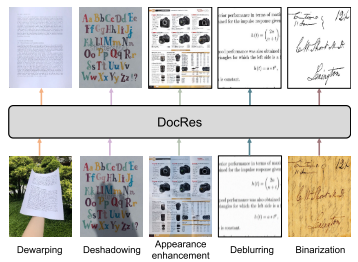
提示学习的例子
-
离散提示
任务:情感分析 目标:判断句子是“积极”还是“消极”。
输入:
1
Prompt: "The movie was amazing. This sentiment is:"
输出:
1
"Positive"
-
连续提示
任务:机器翻译 目标:将英语翻译为法语。
输入:“I like apples.”
提示嵌入:模型内部生成的指示翻译为法语的提示向量(无法被人解读)。
输出:
1
"J'aime les pommes."
-
动态提示
任务:多任务文档修复(展平 + 去阴影 + 去模糊) 目标:根据输入图像的特性,动态调整修复策略。
输入图像:一张同时存在阴影和模糊问题的文档图像。
动态提示生成: 系统分析输入图像特性,生成提示向量:
-
如果检测到阴影问题:提示“去阴影”。
-
如果检测到模糊问题:提示“去模糊”。
输出:修复后的文档图像,阴影和模糊问题被同时解决。
-
输入/输出样本提示
在训练阶段:
- 提供多个任务示例(输入/输出对)用于模型学习任务映射。
- 示例对明确表明任务规则:输入数据和期望的目标结果之间的关系。
在推理阶段:
- 需要提供一组额外的输入/输出样本对告诉模型我们需要执行什么任务。
- 模型根据提示对新输入数据执行类似的操作。
Dynamic task-specific prompt
当前的视觉通用模型的提示信息仅依赖于任务类型。也就是说,提示是固定的,与输入图像无关,无论输入什么样的图像,模型使用的提示都是相同的。这种方法无法捕捉到输入图像的特定信息,因此在处理复杂场景或多样化输入时表现有限。
动态适配:DTSPrompt 根据输入图像和指定任务共同生成提示信息DTSPrompt。提取先验特征:DTSPrompt 生成器会从输入图像中提取与任务相关的先验特征,例如纹理、结构或光影信息,从而为修复任务提供更具体的指导。DTSPrompt 的核心优势在于其动态适配性,能够根据输入图像和任务类型生成特定提示信息。这种方法克服了传统固定提示方式的局限性,提高了模型在多任务、多输入场景中的表现。
Dewarping
去扭曲,利用文档分割模型(Marior)获取文档掩码,作为去扭曲任务的先验特征。此外引入了位置信息(每个像素的坐标),矩阵形状为h*w,将位置信息也作为先验特征。将文档掩码、水平方向坐标、垂直方向坐标通过通道维度串联。
Deshadowing
膨胀操作将图像中亮区域向外扩展(将核覆盖的每个区域内的像素值取最大值,用这个最大值替换核中心像素的值。),逐渐覆盖其周围的像素。中值滤波通过取局部区域的中值替代中心像素值,可以平滑掉膨胀操作后产生的不规则边缘。
把三通道分开,对每个通道先膨胀、后中值滤波,获得一个h * w * 3带有阴影的背景prompt。
Appearance enhancement
文中使用了文档原图和背景图像之间的差异作为外观增强的propmet。
Deblurring
使用输入图像的梯度图作为propmet。
Binarization
Sauvola二值化算法,阈值图,梯度信息作为propmet。
Sauvola二值化算法
Sauvola 算法通过在图像的每个像素周围定义一个局部窗口,在该窗口内计算局部的平均值和标准差,以此为基础动态生成阈值。每个像素值与对应的局部阈值比较,决定该像素属于前景(通常为白色)还是背景(通常为黑色)。
阈值计算:
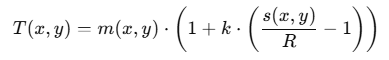
m:局部窗口均值。
s:局部窗口的标准差。
k:超参数,控制对标准差的敏感度。
R:超参数,动态范围(通常为 128,用于归一化标准差)。
Prompt fusion and restoration network
把DTSPrompt和图片特征进行简单的融合(通道维度的concat)。恢复网络选用的是Restormer。
总结
这篇文章有个非常致命的问题,需要明确指出要执行什么任务。