CDFormer: When Degradation Prediction Embraces Diffusion Model for Blind Image Super-Resolution
这篇文章由南京航空航天大学撰写,发表在2024CVPR。
链接:CVPR 2024 Open Access Repository (thecvf.com)
代码链接:https://github.com/I2-Multimedia-Lab/CDFormer
这篇文章提出了一种新的盲图像超分辨率方法,引入了一种从高低分辨率图像对中学习退化和内容信息的方法,并通过扩散模型从低分辨率图像中重建CDP。提出了CDFormerSR网络,能够有效利用CDP,通过注入模块和交叉流机制改进特征表示,从而增强图像重建质量。
STAGE 1
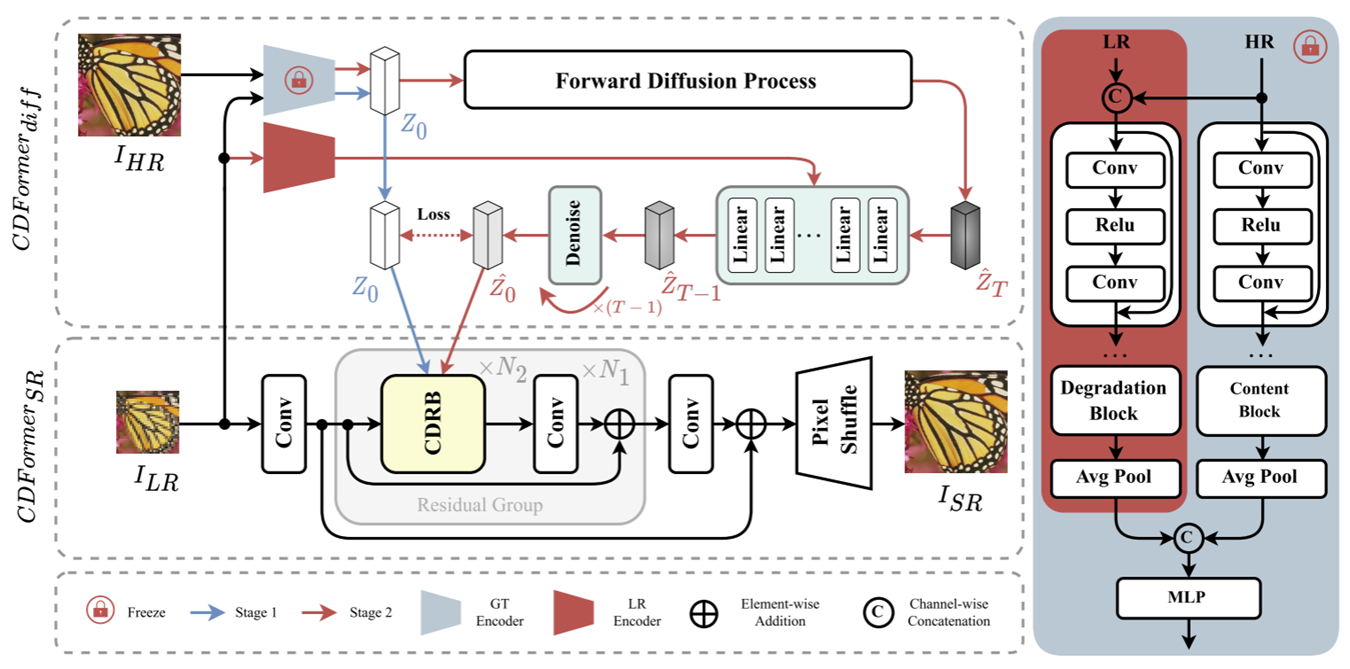
第一阶段是蓝线部分。
第一阶段输入高分辨率图像和低分辨率图像,训练EGT和CDFormerSR。EGT用来提取所谓的CDP,EGT左侧用来提出降质信息,右侧用来提取内容细节信息. EGT的输出就是所谓的CDP。左侧输入为LR和HR通道维度的连接(HR需要进行Pixel-Unshuffle操作),右侧输入为HR。
CDFormerSR目标是在CDP的指导下重建高分辨率的图像,CDP通过CDIM注入。
CDIM是一种内容和退化信息注入模块,公式如下:
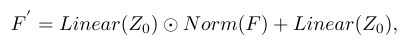
其中,
Z0是CDP。
F是特征图。
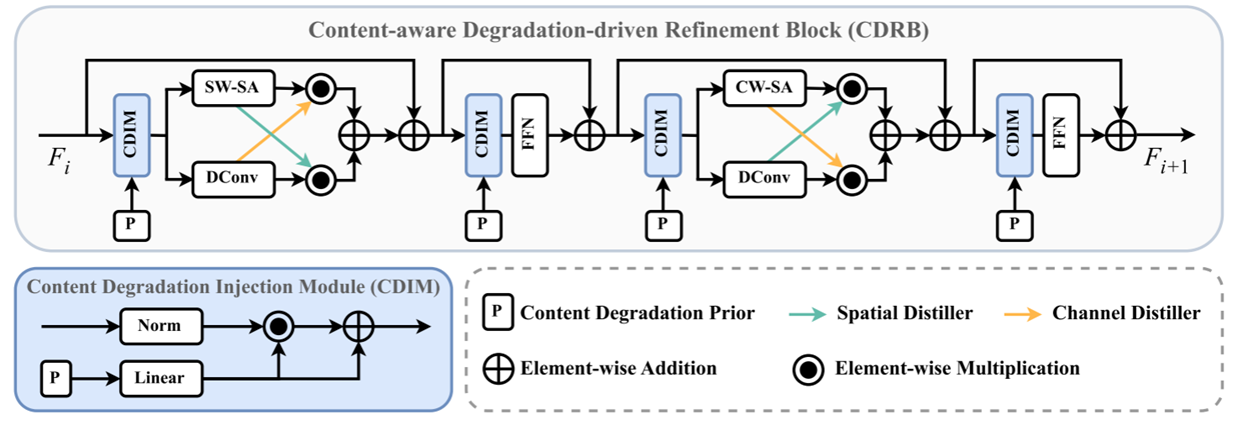
CDRB结合了空间注意力和通道注意力机制,并通过互流机制进一步结合CNN和Transformer特征。
Interflow Mechanism(互流机制):
Channel Distiller:transforms to 1 x 1 x C。通过全局平均池化。
Spatial Distiller:transforms to H x W x 1。通过1 * 1卷积核。
第一阶段损失:
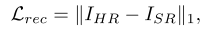
其中:
IHR代表高分辨率图像。
ISR代表重建后的图像。
STAGE 2
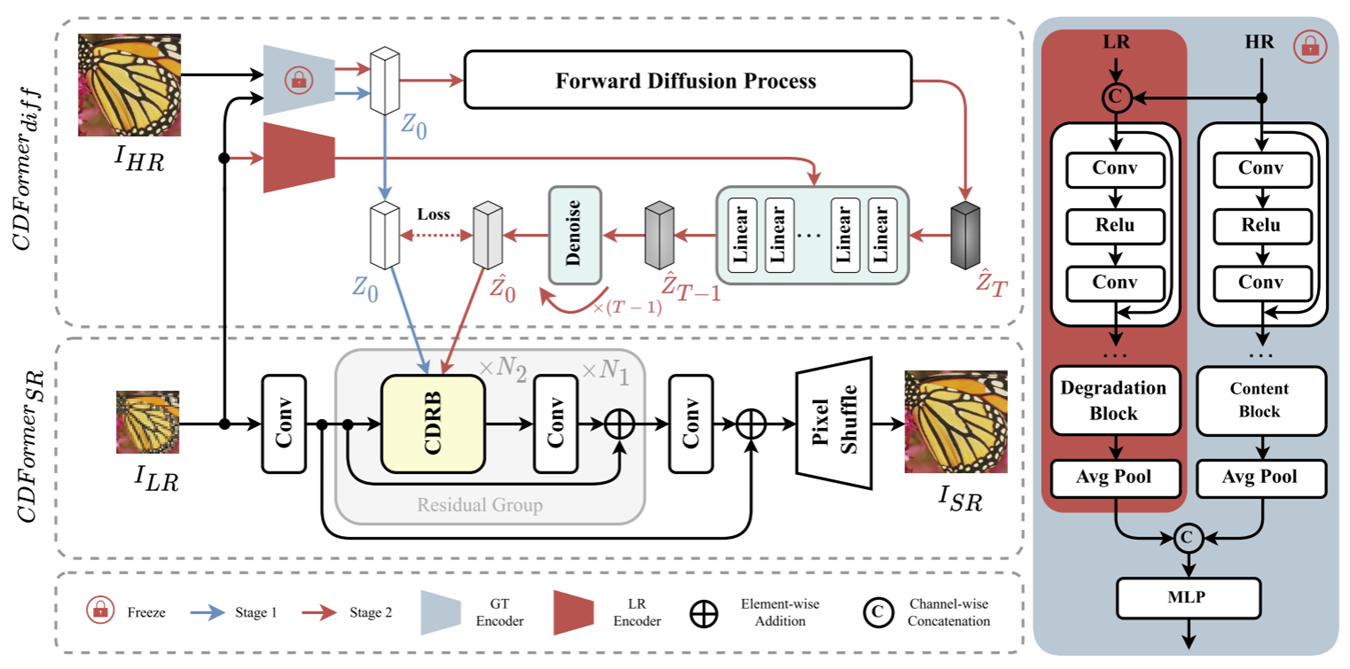
第二阶段输入是低分辨率图像,使用第一阶段生成的CDP不断加噪,利用Diffusion来去噪,每次去噪将低分辨率图像信息融入(从LREncoder获得),在这里,去噪过程并没有持续很多次,文中只进行了4次(效果就很好了,因为这篇文章并不是想要去利用Diffusion重建图像,只是想获得一些信息)。去噪完成后就获得了CDP,将CDP注入CDFormerSR网络。
第二阶段的损失:
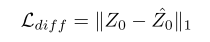
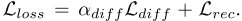
其中:
Z0是第一阶段生成的CDP。