Text Image Super-Resolution
| 年份 | 标题 | 介绍 |
|---|---|---|
| 2015 | Image Super-Resolution Using Deep Convolutional Networks | 第一个把深度学习用在超分任务中的工作 |
| 2015 | Boosting Optical Character Recognition: A Super-Resolution Approach | 第一个把深度学习用在文本图像超分任务中的工作 |
| 2018 | Binary Document Image Super Resolution for Improved Readability and OCR Performance | 第一个二值化的文本图像超分辨率工作 |
| 2019 | TextSR: Content-Aware Text Super-Resolution Guided by Recognition | 第一个专门研究文本超分辨率的工作、利用GAN |
| 2020 | Scene Text Image Super-Resolution in the Wild | 第一个场景文本超分辨率的真实数据集 |
| 2021 | Scene Text Telescope: Text-Focused Scene Image Super-Resolution | 利用Transformer |
| 2021 | Text Prior Guided Scene Text Image Super-Resolution | 利用OCR模型 |
| 2022 | Blueprint Separable Residual Network for Efficient Image Super-Resolution | 量化 |
| 2023 | Diffusion-based Blind Text Image Super-Resolution | 利用Diffusion |
| 2024 | Scene Text Image Super-Resolution with CLIP Prior Guidance | 利用CLIP |
| 2024 | Pragmatic degradation learning for scene text image super-resolution with data-training strategy | 预训练、微调 |
Image Super-Resolution Using Deep Convolutional Networks
年份:2015
期刊/会议:IEEE Transactions on Pattern Analysis and Machine Intelligence
单位:香港中文大学
标题:基于深度卷积网络的图像超分辨率
GPU:
介绍:超分的开山之作,使用三层卷积神经网络实现超分,第一层实现特征提取,第二层实现映射,第三层重建。
个人理解:使用卷积操作来替代稀疏编码SR的映射操作。
Boosting Optical Character Recognition: A Super-Resolution Approach
年份:2015
期刊/会议:arxiv
单位:香港中文大学
标题:提升光学字符识别:一种超分辨率方法
GPU:
介绍:采用模型组合策略进行比赛。贪心算法。
个人理解:比较重视调参,贪心算法是一种比赛策略。
Binary Document Image Super Resolution for Improved Readability and OCR Performance
年份:2018
期刊/会议:arxiv
单位:
标题:用于提高可读性和OCR性能的二值文档图像超分辨率
GPU:
介绍:第一个二值化的文本图像超分辨率工作,这项工作旨在通过在线创建电子文本版本来保护古代泰米尔文学。提出了全新衡量的标准,用ocr模型来识别超分后的图像,用ocr的准确率来衡量超分的效果。
Convolution-Transposed Convolution Model

Parallel Stream Convolution Model
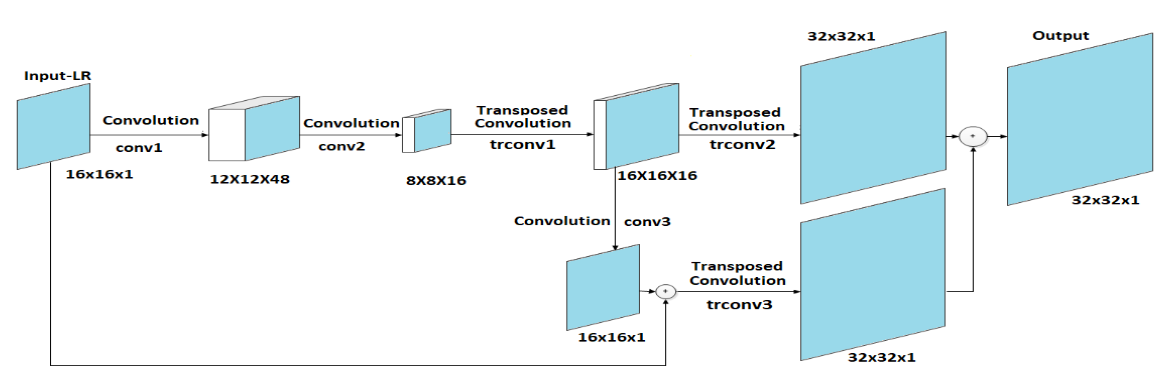
CTC-Sub-pixel Convolution Model

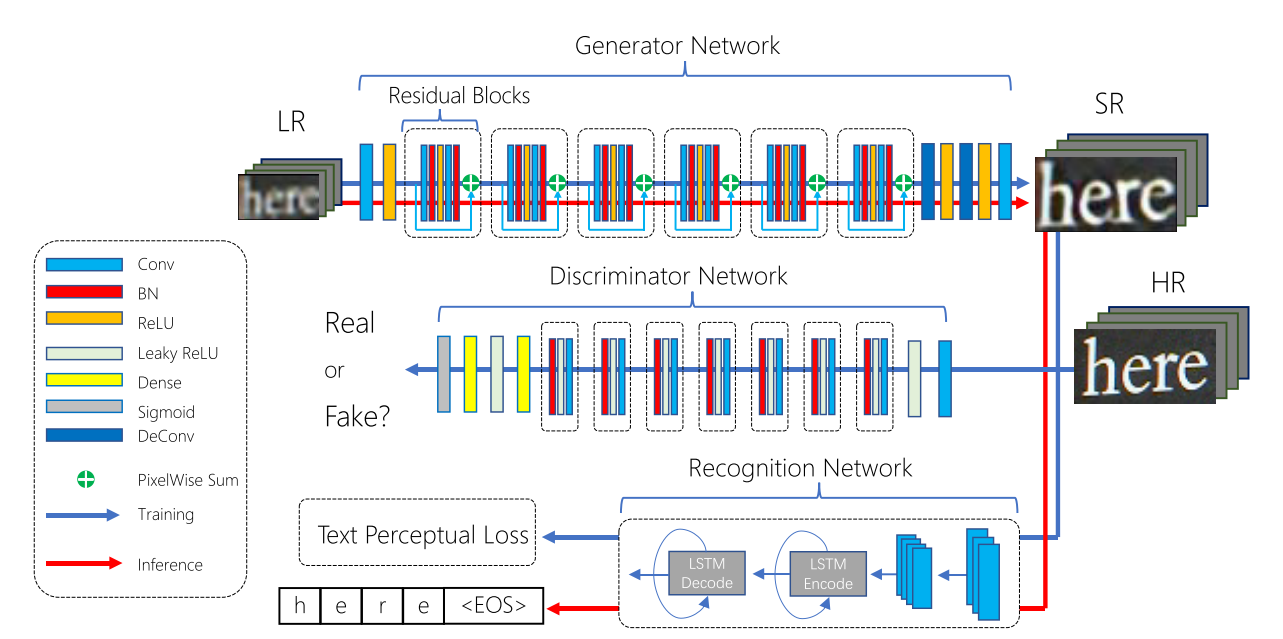
TextSR: Content-Aware Text Super-Resolution Guided by Recognition
年份:2019
期刊/会议:arxiv
单位:同济大学
标题:基于识别引导的内容感知文本超分辨率
GPU:4 * Tesla M40
介绍:第一个专门研究文本超分辨率的工作。结合了超分辨率网络和文本识别网络。把GAN和ASERT结合。使用ASERT来计算TPL(文本感知损失)。把文本感知损失、内容损失和对抗损失联合优化。
损失
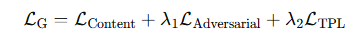
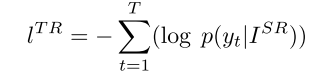
个人理解:核心在于损失函数。
Scene Text Image Super-Resolution in the Wild
年份:2020
期刊/会议:ECCV
单位:商汤
标题:自然场景文本图像超分辨率
GPU:4 * NVIDIA RTX 1080Ti
介绍:这项工作制作了一个场景文本超分辨率的真实数据集TextZoom(以往LR图像是合成的,这个数据集LR也是相机拍摄的)。
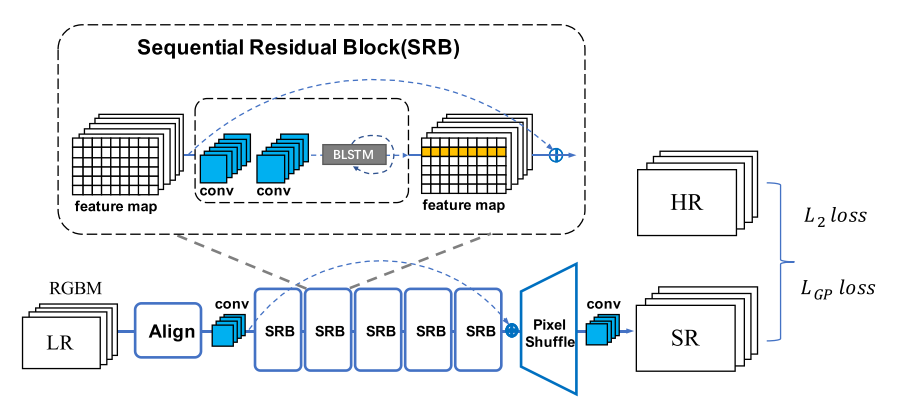
引入了梯度的损失
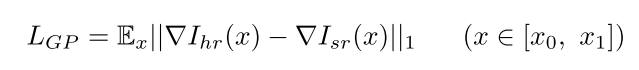
Scene Text Telescope: Text-Focused Scene Image Super-Resolution
年份:2021
期刊/会议:CVPR
单位:复旦大学
标题:
GPU:4 * NVIDIA TITAN Xp
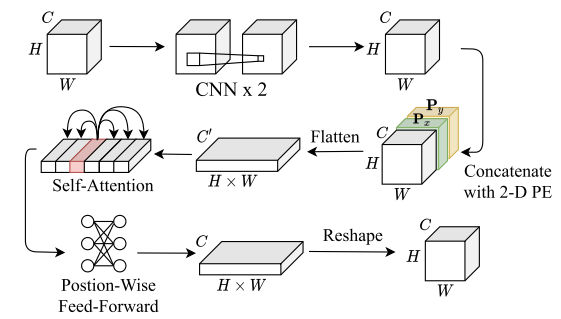
介绍:引入了STN网络对图像进行预处理(把字体变正),引入了transformer,
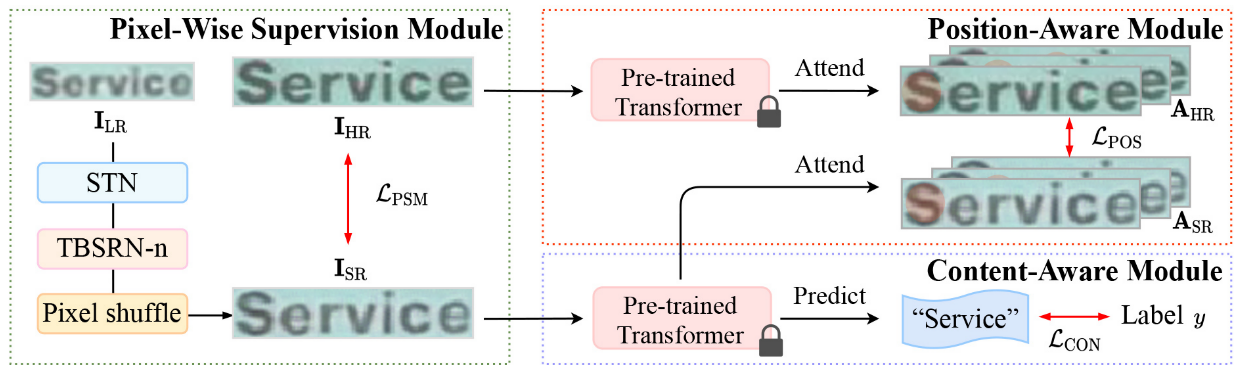
损失函数:

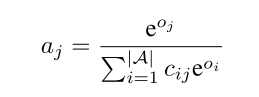
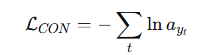
个人理解:混淆系数、损失函数是最大亮点。
Text Prior Guided Scene Text Image Super-Resolution
年份:2021
期刊/会议:IEEE TRANSACTIONS ON IMAGE PROCESSING
单位:香港理工大学
标题:文本先验引导的场景文本图像超分辨率
GPU:NVIDIA RTX 2080Ti
介绍:首次将文本识别模型带入进文本图像超分领域。通过文本概率(CRNN)的指导来生成更好的高分辨率图像。通道维度拼接。使用双三次插值。给文本概率分支也设置了一个损失函数。
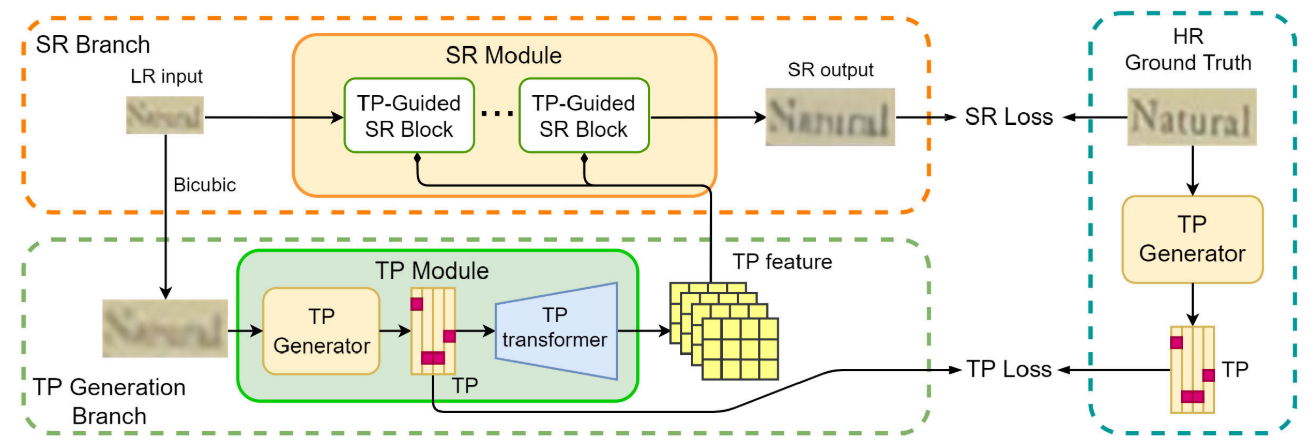
提出了一个多阶段(三)策略非常有意思。
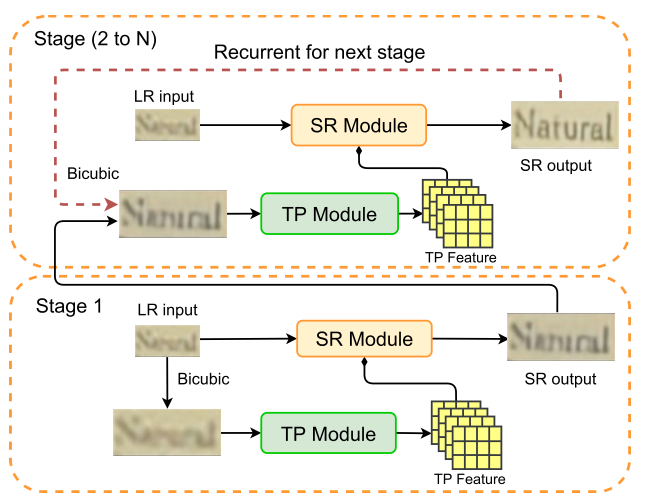
个人理解:可以说是具有划时代意义的工作,后续的绝大部分工作都在模仿。大部分工作中的SR模块都是把以前的工作直接拿过来用的。
Blueprint Separable Residual Network for Efficient Image Super-Resolution
年份:2022
期刊/会议:CVPRW
单位:深圳市计算机视觉与模式识别重点实验室
标题:用于高效图像超分辨率的蓝图可分离残差网络
GPU:2 * GeForce RTX 3090
介绍:通过替换卷积核来实现量化。
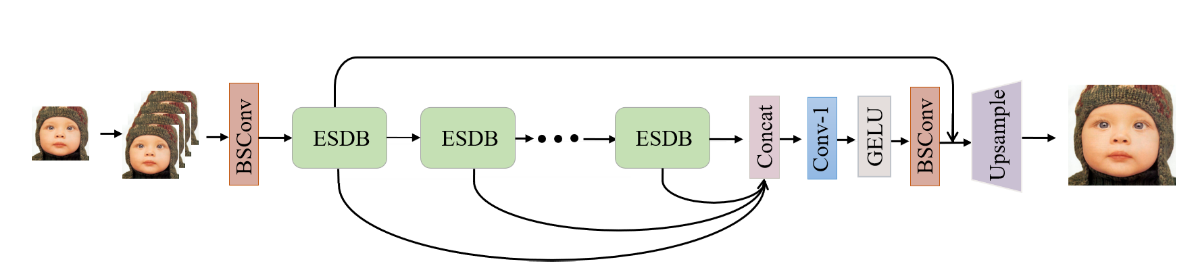
核心就在于做了空间层面和通道层面的解耦。(如果输入:3 * 3 * 3;对于普通卷积:3 * 3 * 3 * 4;对于解耦后的卷积:3 * 3 * 3,1 * 1 * 3 * 4)
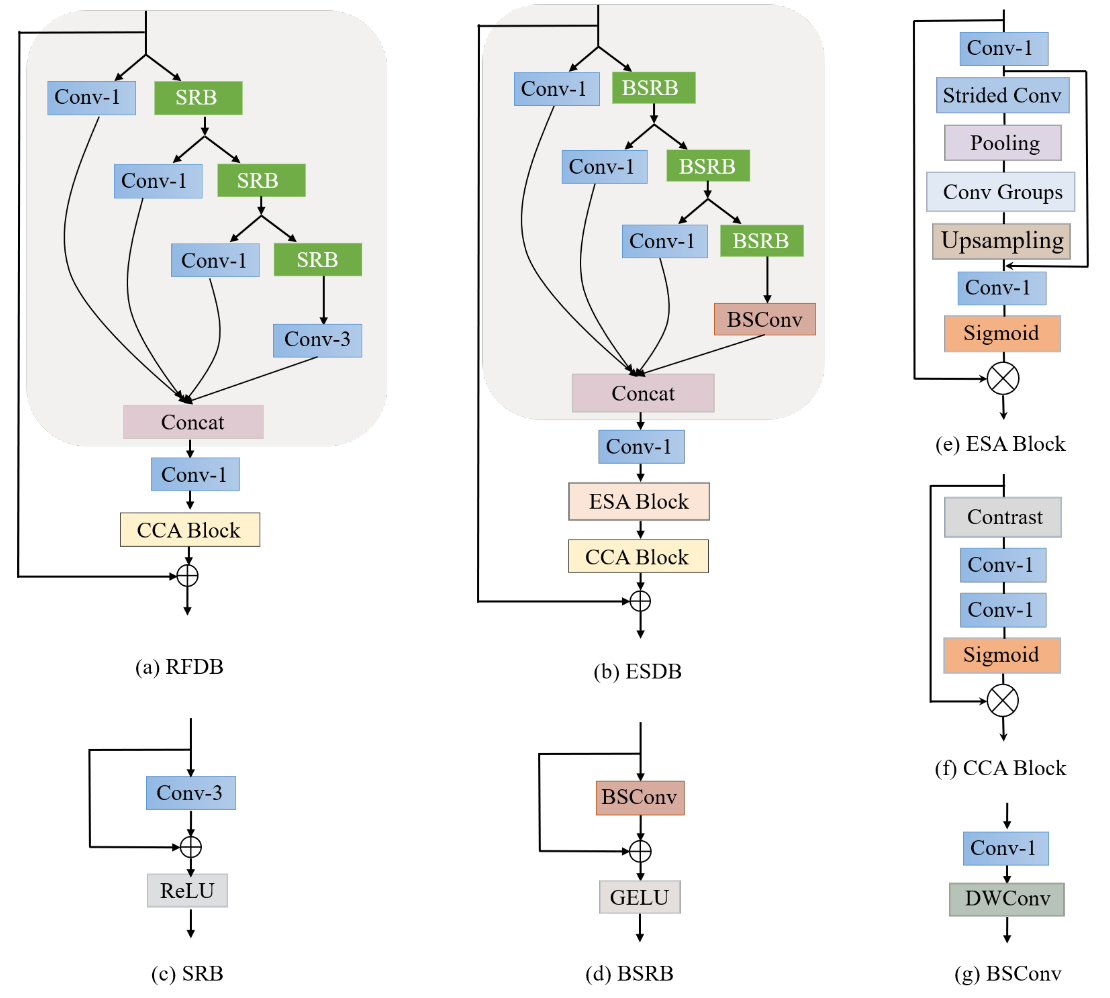
个人理解:主要是利用深度可分离卷积进行参数减少。
Diffusion-based Blind Text Image Super-Resolution
年份:2023
期刊/会议:CVPR
单位:北京理工大大学
标题:基于扩散的盲文本图像超分辨率
GPU:
介绍:利用transformer来提取文本先验,作为条件传入扩散模型。
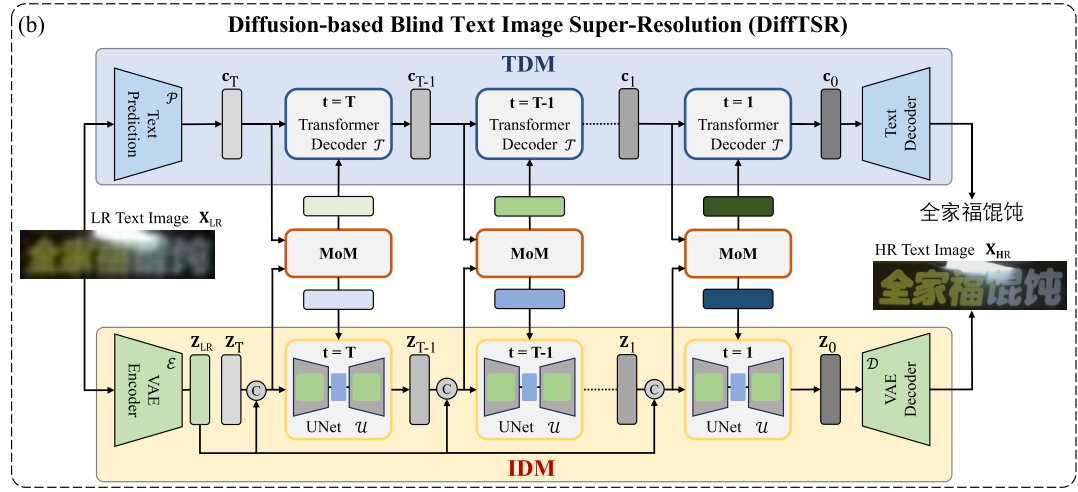
个人理解:将transformer的重复过程解释为文本扩散。
Scene Text Image Super-Resolution with CLIP Prior Guidance
年份:2024
期刊/会议:ICPR
单位:印度海得拉巴大学
标题:基于CLIP先验引导的场景文本图像超分辨率
介绍:微调CLIP(使用TextZoom对CLIP微调),
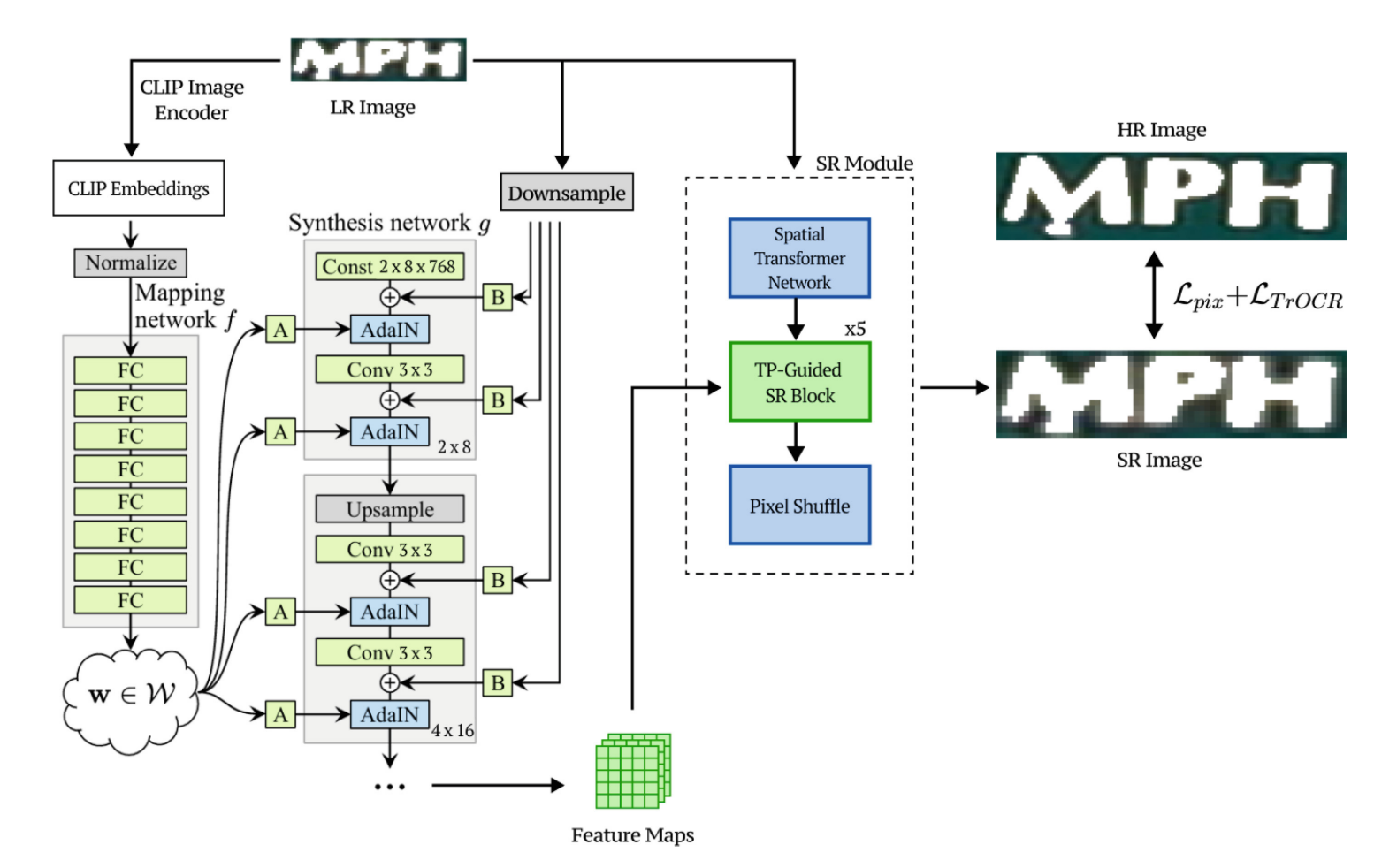
const是一个矩阵,值全为1(或者其他),用来作为StyleGAN2的输入。
AdaInN实际上是一个特征融合模块计算公式如下:
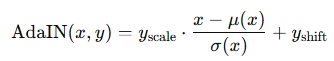
TP-Guided SR Block:通道维度拼接,然后进行投影。
引入了一个新的loss:
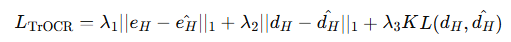
个人理解:将CLIP、GAN和目前已有的STISR融合构建一个新的SR网络,计算损失时注意到了文本识别的损失。
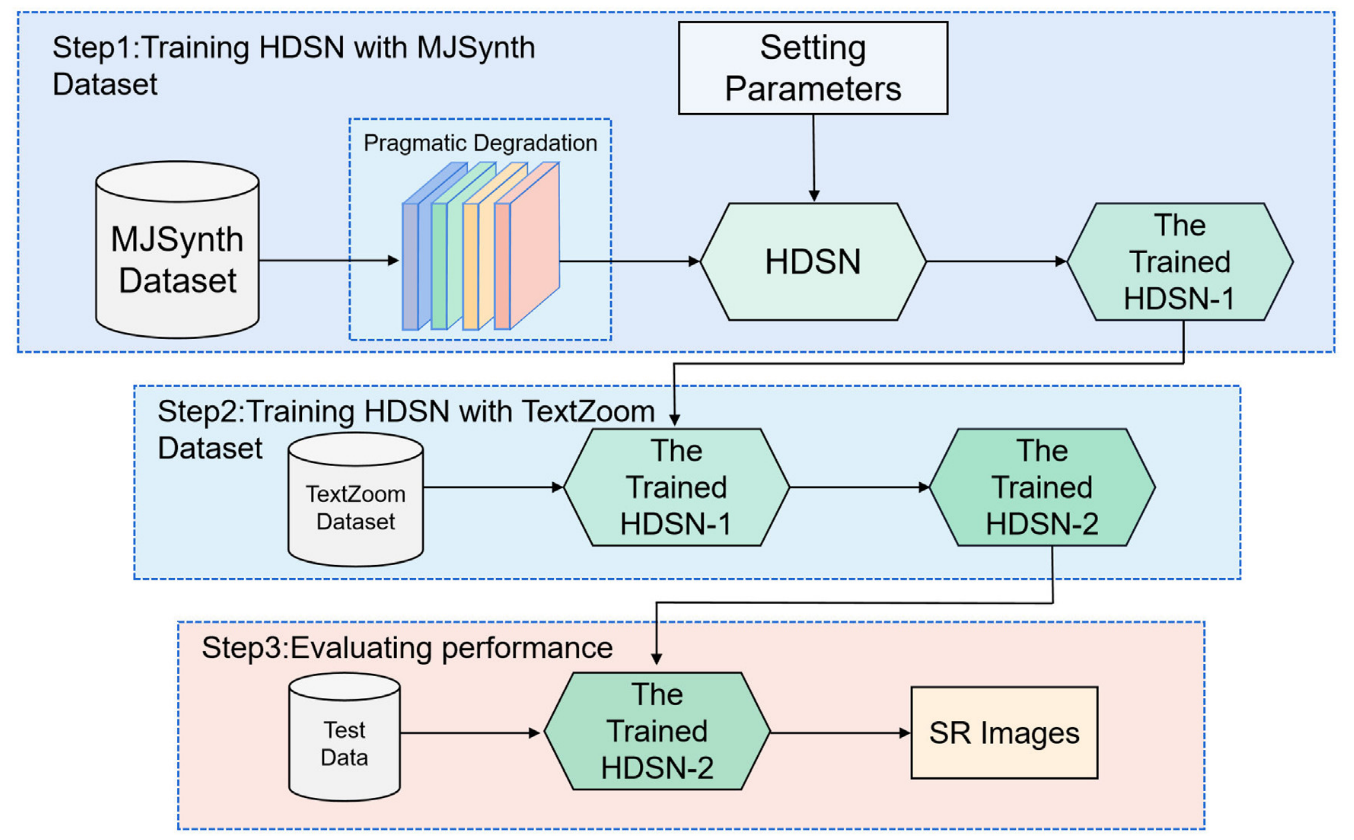
Pragmatic degradation learning for scene text image super-resolution with data-training strategy
年份:2024
期刊/会议:Knowledge-Based Systems
单位:浙江科技大学
标题:针对场景文本图像超分辨率的实用退化学习与数据训练策略
介绍:目前大部分数据集一般基于双三次下采样、单一的模糊核、单一的加噪过程,无法模拟真实世界各种各样的情况。文章解决了退化模型使用的退化过程与真实图像退化过程不匹配的问腿。这项工作使用各向同性高斯模糊核和各向异性高斯模糊核以扩展模糊核的适用性;引入常见的 JPEG 压缩噪声、泊松噪声、高斯噪声以及散斑噪声来减少这种负面影响;对HR图像随机生成多种不同退化程度的LR图像。
个人理解:这项工作提出一个三阶段策略,使用了合成数据集进行大规模训练,最后使用真实数据集进行微调。由于合成数据集模拟了大部分可能的降质情况,理论上通过预训练的超分模型只需要微调就可以在大部分数据集上使用。
相关知识:
-
单线性插值算法
基于x或者y其中之一。 \(f=af_1 + bf_2(a+b=1)\) a、b表示权重,f表示像素值。
-
双线性插值算法
如何从目标图像坐标得到对应原图像坐标:
实例:目标图像坐标2,3;原图像和目标图像比3 : 4。那么原图像坐标就是2 * 3 : 4, 3 * 3 : 4。
这个时候原图像坐标不是整数,很可能和四个点相关。
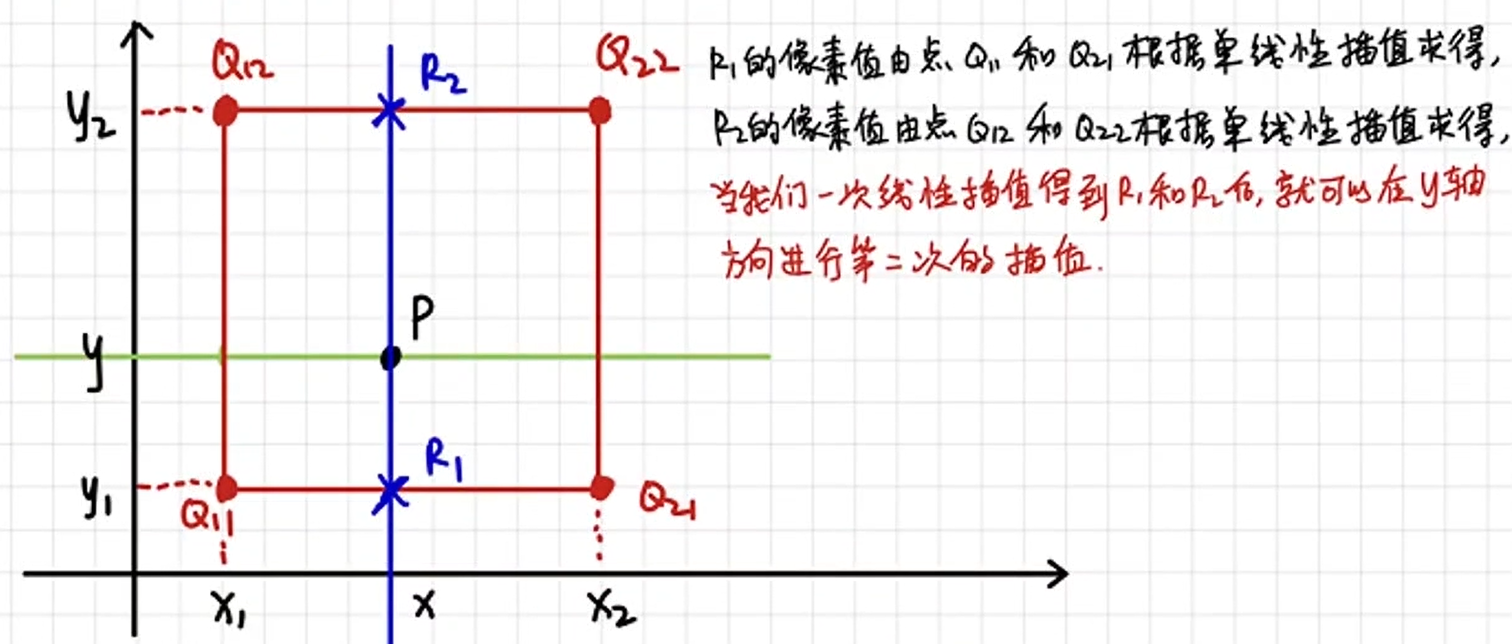
这个时候我们在x轴方向进行两次单线性插值,然后在y轴方向进行一次单线性插值。
-
双三次插值算法
双指的是x、y两个方向,三次是说我们在计算目标像素点周围像素权重的时候使用一个三次项的公式来计算。
使用16个像素点,
权重计算公式如下:

得到权重后,16个像素值乘x方向权重,乘y方向权重。
-
深度可分离卷积
-
反卷积
-
梯度场
假设有一张简单的3×3灰度图像,表示像素值为:
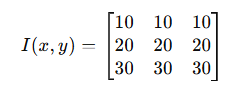
水平方向上(右边减左边),相邻像素的差值为:
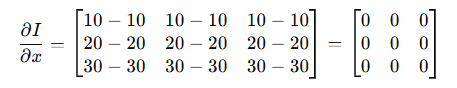
垂直方向上(上面减下面),相邻像素的差值为:
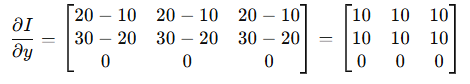
梯度场由水平和垂直梯度组成,记为:
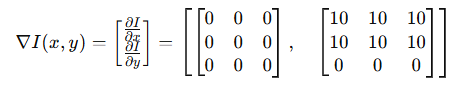
也可以使用算子(固定数值的矩阵)。