Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution
介绍
标题:Upscale-A-Video: 面向真实世界视频超分辨率的时序一致性扩散模型
期刊/会议:CVPR
年份:2024
单位:南洋理工大学
GPU:32 * NVIDIA A100
概述:这是一个用于视频超分辨率的潜在扩散模型,主要解决时序一致性的问题。作者通过更改U-net网络来保证局部一致性,通过一个无需训练的流引导的递归潜在传播模块保证全局一致性。
方法
在潜在扩散模型(LDM)中融入了局部(就是更改了U-Net)和全局模块(Global)。在每个扩散时间步(t = 1, 2…T),视频被分割成多个片段(8帧)通过包含时间层的 U-Net 进行处理,以确保每个片段内的一致性。不是每一个时间步都使用全局约束,当时间步处于用户指定的全局细化步骤(T∗)内,在推理过程中会采用循环潜在传播模块来提高片段间的一致性。
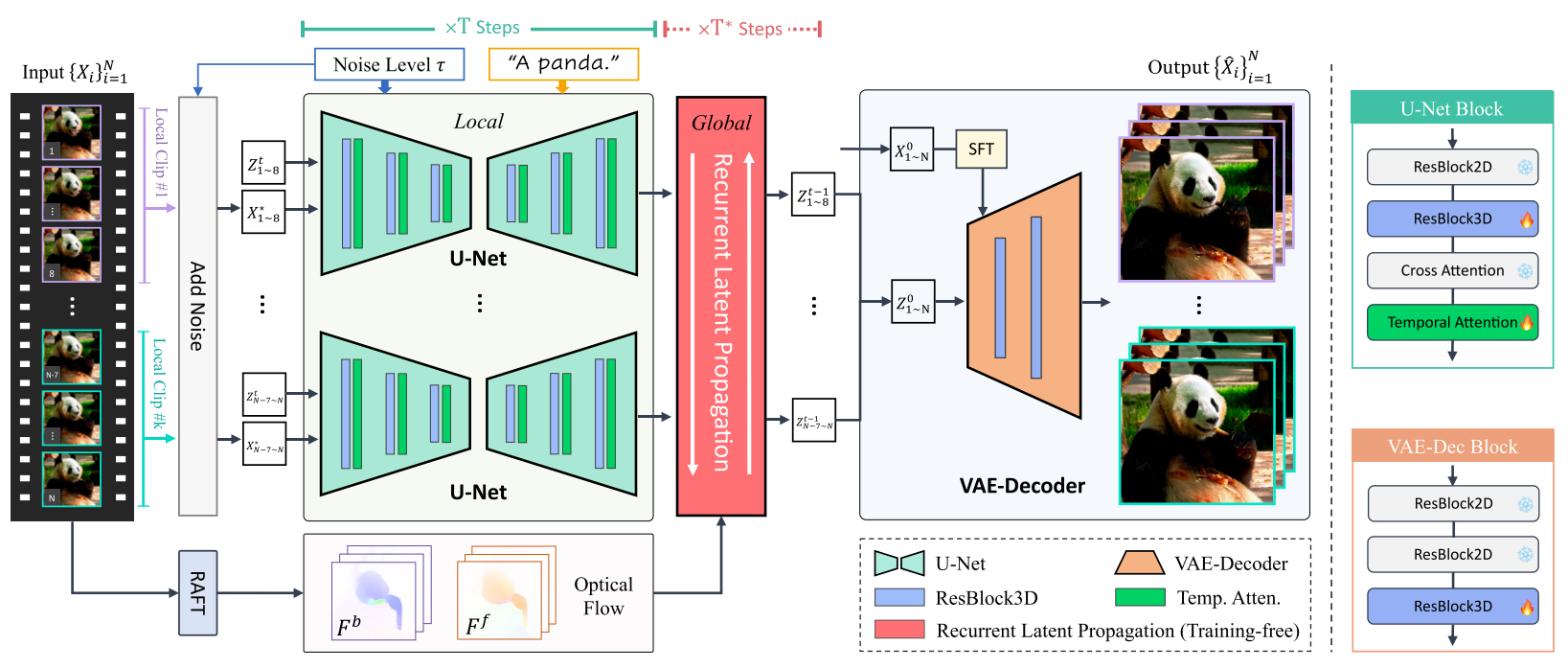
整体流程
整体流程大概是这样的,先正常加噪(时间步T),然后文章中还要对低分辨率图像进行一个随机加噪,将这两个拼接到一起送进U-Net,与此同时文章中使用其他的模型对视频进行了预测得到了视频的文字描述,用户也可以手动输入文字描述,这两个文字描述将加到一起最为后续扩散条件(会使用交叉注意力机制融合)。为了契合视频,这项工作稍微修改了一下网络结构,2D卷积换成了3D卷积。
微调时间 U-Net
这项工作基于三维卷积的时间注意力层和三维残差块作为时间层,并将它们插入到预训练好的空间层之间。冻结其他层只训练后加入的层。
微调时间 VAE 解码器
和微调U-Net差不多,增加了三维残差块,冻结其他层只训练后加入的层。
跨视频段的全局一致性
上述的时间层仅限于处理局部序列(在UNet设置中为八帧),这项工作提出了一种无需训练的、基于光流的潜在空间循环传播模块,该模块通过前向和后向的双向传播,确保长输入视频的全局时间一致性。
首先使用RAFT来估计光流,然后通过前向后向一致性误差评估光流的有效性,会设置一个阈值,当E(误差)小于阈值这个光流才被视为有效(有效时M=1,无效时M=0)。
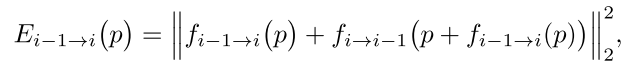
上式 i-1 -> i 表示前向,i -> i-1 表示后向。
然后通过下面的公式来改变特征
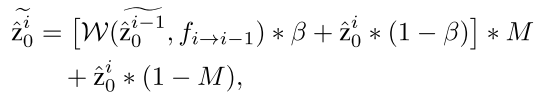
上述公式W代表扭曲操作,其中最重要的是M,当光流估计有效前一帧和后一帧通过光流结合,当光流估计无效只保留当前帧信息。