Towards Robust Scene Text Image Super-resolution via Explicit Location Enhancement
介绍
标题:基于显式位置增强的场景文本图像超分辨率研究
单位:清华大学
期刊/会议:IJCAI
这项工作提出文本图像超分的目的是为了后续的字符识别,从某种意义上来说我们只需要重视前景就好,文字信息以外的信息甚至可以忽略。
方法
概述
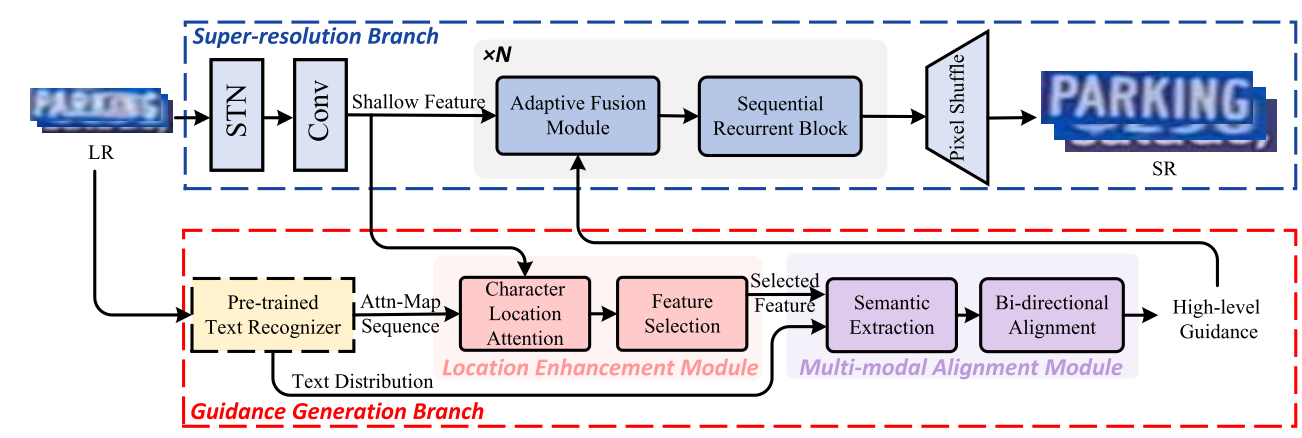
低分辨率图像首先通过空间变换网络STN进行校正,然后使用浅层卷积神经网络提取浅层特征X,随后X将会进入引导生成分支和超分辨率分支。在引导生成分支中,位置增强模块以注意力序列和X作为输入,生成选定特征,然后多模态对齐模块使用文本分布和选定特征进行视觉-语义双向对齐。在超分辨率分支中X会经过N个堆叠的模块,每个模块包含一个自适应融合模块和一个序列循环块。最后,通过 PixelShuffle 操作增加空间尺度。
位置增强模块
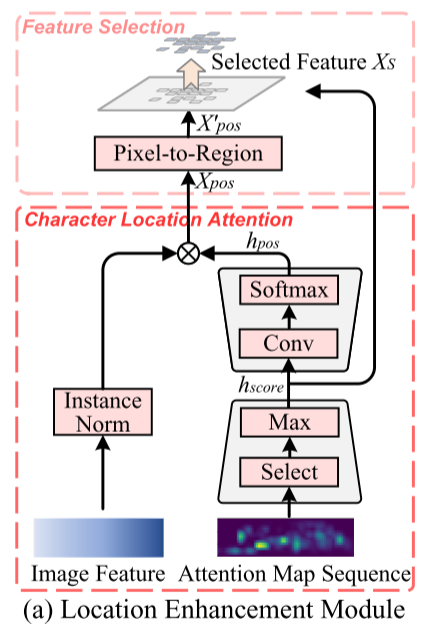
使用一个预训练好的文本识别器生成注意力图序列,这个时候形状是T H W。
压缩
如果有效长度为L,那么只选取前L个注意力图,其他丢弃。然后将这L个注意力图拼接,以通道维度,选最大值,将维度减少到1。这种操作过后我觉得肯定丢失了语义信息,但是保留了位置信息。
扩张
把一维的位置信息通过卷积扩张,然后通过softmax函数计算出概率。
归一化
对浅层信息进行了一些简单的归一化,然后与上述的概率相乘。
特征选择
利用前面获得的一维注意力图来进行特征选择,选前K个较大的值得到前景坐标集。然后利用前景坐标集收集前景特征,在这个过程中为了避免领域特征丢失在局部区域进行加权求和。
多模态对准模块
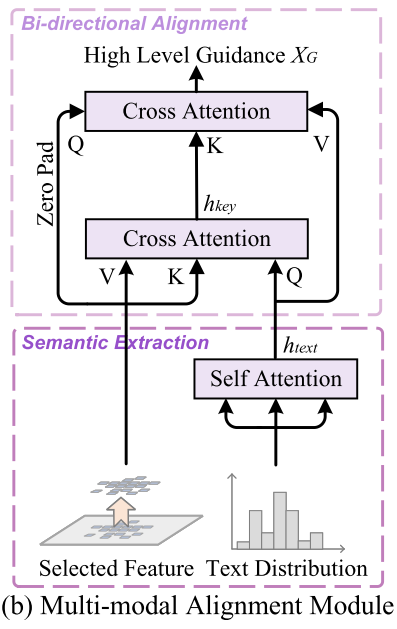
语义提取
通过线性投影和自注意力模块,对文本识别器得到的文本分布进行语义提取。
双向对齐
首先通过线性投影和自注意力模块,对文本识别器得到的文本分布进行语义提取。然后进行了两次的交叉注意力,生成高级指导信息。
自适应融合模块
实际上就是提出了一个融合特征的方法,将高级引导信息自适应地融入到超分辨率分支中。给定图像特征(它是或者是前一个模块的输出)以及高级引导信息,我们首先沿着通道维度将它们连接起来,然后进行三个并行的1 × 1卷积操作,将投影到三个不同的特征空间中,分别叫做X1,X2,X3。对X1执行通道注意力机制,并将得到的分数与X2相乘,以生成通道注意力特征,再将该特征与X3相加,